Preamble
It is sometimes necessary to join or search data from various absolutely regular and independent PostgreSQL databases (i.e., no built-in clustering extensions or the like are in use) in the heyday of bigdata and people running lots of Postgres databases in order to present it as one logical entity. Consider logical clustering in sales reporting or tying click-stream data to sales orders based on customer IDs.
How then do you handle such impromptu tasks? Naturally, it could be resolved at the application level with some straightforward scripting, but let’s say we only have SQL knowledge. Fortunately, PostgreSQL (along with the ecosystem) offers some options right out of the box. There are also some third-party tools available for situations where you, for example, are unable to use the Postgres options (no superuser rights are allowed, and extensions cannot be installed). Therefore, let’s examine the following 4 possibilities:
- Extension for dblink
- Extension for PostgreSQL
- SQL engine distributed by Presto
- Virtual driver for JDBC for Unity and SquirrelL SQL client
The dblink extension
The most straightforward method to join different Postgres databases is probably the one that has been in use for a very long time. In essence, all you have to do is declare a named connection, create the extension (which needs “contrib”), and use the dblink function to specify a query that includes a list of output columns and their datatypes. After the query is sent to the specified connection, the pulled-in dataset will be treated as a regular subselect, allowing one to then utilize all that Postgres has to offer!
Things to remember
- Remote data is downloaded onto the server without any additional information (statistics, indexes), so if there are many operations occurring on higher nodes and the data amounts are large, performance will likely not be at its best.
- In order to reduce the IO penalty when working with larger amounts of data retrieved from dblink, increase work_mem/temp_buffers.
- The connection can also be declared directly in the dblink function, but if there are more databases involved, your SQL-s may become a bit cumbersome.
Pros include flexibility in connecting to X number of Postgres DBs and the simplest setup possible.
Cons: SQLs may become ugly for multiple joins, larger datasets may experience performance issues, and only basic transaction support
The Postgres foreign-data wrapper
The Postgres foreign-data wrapper (postgres_fdw extension, available in “contrib”) has been around since version 9.3 and is an improvement over dblink. It is well suited for more permanent data crunching, and with the addition of “foreign table inheritance” in version 9.6, one could even build complex sharding/scaling architectures on top of it. What you essentially get is a permanent “symlink / synonym” to a table or view on another database, with the advantage that the local Postgres database (where the user is connected) already has the column details on the table, especially size and data distribution statistics, so it can create better execution plans. True, the plans weren’t always the best in older versions of Postgres, but the 9.6 version recently received a lot of attention in that regard. NB! The FDW also supports transactions and writing/changing data!
Overview of the setup procedures:
- Install the add-on.
- Establish a foreign server
- Create a user mapping so that different users can access the remote tables and perform different operations.
- Create foreign tables by manually defining columns or by automatically importing entire tables or schemas (9.5+)
- Perform some SQL.
Benefits include performance, allowing data modifications, and full transaction support.
Cons: The setup and user management process requires quite a few steps.
Presto
Presto is an open source, distributed SQL query engine that is not really Postgres-centric but rather DB-agnostic. It is designed to connect the widest range of “bigdata” datasources via SQL. It was designed by Facebook to handle Terabytes of data for analytical workloads, so it should handle your data amounts efficiently. Although it isn’t the most lightweight approach because it is essentially a Java-based query parser/coordinator/worker framework, it is still worth a shot even for smaller amounts of data. It assumes nodes with lots of RAM for larger amounts of data!
Although setup may seem intimidating at first, it will only take a few minutes to get going because of the excellent documentation. The process in general is shown below.
- Obtain the tarball now.
- Create a few straightforward configuration files as instructed in the deployment manual.
- Use “bin/launcher start” to launch the server.
- With “./presto -server localhost:8080 -catalog hive -schema default,” the query client will be launched.
- Execute some SQL queries over separate DBs.
presto:default> SELECT count(*) FROM postgres.public.t1 x INNER JOIN kala.public.t1 y ON x.c1 = y.c1; _col0 ------- 1 (1 row) Query 20170731_122315_00004_s3nte, FINISHED, 1 node Splits: 67 total, 67 done (100.00%) 0:00 [3 rows, 0B] [12 rows/s, 0B/s]
Many data sources, good SQL support, excellent documentation, and monitoring dashboard are positives.
Cons: Requires full SQL re-implementation, which means you lose Postgres analytic functions, etc.
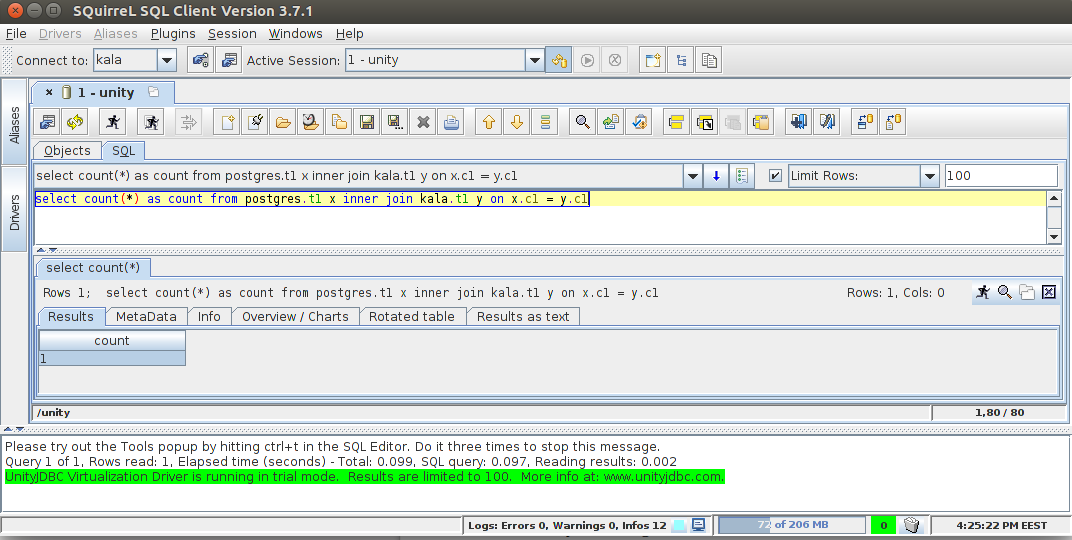
UnityJDBC + SQuirrelL SQL Client
Another “generic” method to connect to various databases, including Postgres, using standard SQL is to use the “virtual datasource” plugin for the well-known SQL client SQuirreL. SQuirreL simply seems to have more documentation, despite the fact that there are other SQL clients available.
The general process in this case is as follows:
- the SQuirreL SQL client installation
- Put the Unity JDBC driver and Postgres JDBC in the “lib” folder.
- Create “aliases” for standard Postgres data sources in SQuirreL.
- Publish the virtual driver
- Join the virtual driver, then add previously registered “normal” data sources to the session on the following screen.
- Start SQL
Pros include user-level access, user-level setup, and support for numerous other data sources, including MySQL, MSSQL, Oracle, and MongoDB
Cons: Commercial license; trial mode limited to 100 result rows and two databases; SQL-92 compliant, so don’t expect fancy Postgres syntax to work.
That’s all. I hope you learned something new, and please let me know in the comments if you are aware of any additional inventive methods for the ad hoc blending of data from various Postgres databases. Thanks a lot!
About Enteros
Enteros offers a patented database performance management SaaS platform. It finds the root causes of complex database scalability and performance problems that affect business across a growing number of cloud, RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
How to Enable Intelligent Wealth Growth with Enteros Database Analytics, RevOps Automation, and Gen AI
- 24 June 2026
- Software Engineering
Introduction Wealth management and investment organizations are entering a new era defined by data-driven decision-making, AI-powered advisory systems, and highly automated operational environments. As client expectations grow and financial markets become more dynamic, firms must continuously improve performance, efficiency, and personalization to remain competitive. Modern wealth organizations now operate complex ecosystems that include: Portfolio management … Continue reading “How to Enable Intelligent Wealth Growth with Enteros Database Analytics, RevOps Automation, and Gen AI”
How to Improve Financial Cost Visibility with Enteros Database Management Platform and Cost Attribution Analytics
Introduction The financial services industry is rapidly evolving as banks, insurance companies, fintech platforms, and investment firms modernize their digital infrastructure to support real-time transactions, data-driven decision-making, and highly personalized customer experiences. Modern financial organizations operate complex ecosystems that include: Core banking systems Digital payment platforms Investment and trading systems Risk management applications Fraud detection … Continue reading “How to Improve Financial Cost Visibility with Enteros Database Management Platform and Cost Attribution Analytics”
How AI-Driven Database Monitoring Enhances Business Continuity and Resilience
In today’s always-on digital economy, business continuity and operational resilience have become essential for enterprise success. Organizations depend heavily on digital systems to support customer interactions, financial transactions, supply chain operations, analytics, internal workflows, and real-time decision-making. Any disruption to these systems can lead to significant financial loss, operational inefficiencies, and reputational damage. At the … Continue reading “How AI-Driven Database Monitoring Enhances Business Continuity and Resilience”
Reducing Application Latency with Intelligent Database Performance Management
In today’s digital economy, application speed is directly tied to business success. Whether users are shopping online, using banking applications, streaming content, accessing SaaS platforms, or interacting with enterprise systems, they expect fast and seamless experiences. Even minor delays can impact user satisfaction, engagement, and revenue. Application latency has become one of the most important … Continue reading “Reducing Application Latency with Intelligent Database Performance Management”